高速な圧縮辞書ライブラリXcdatをリリースしました
圧縮ダブル配列を利用したトライ辞書ライブラリXcdatをリリースしました。
頑張って整備したので、簡単ではありますが解説記事を書いて宣伝したいと思います。Star頂けるととても喜びます。
どんなライブラリ?
トライ辞書を実現するライブラリとしては、ダブル配列を使ったDartsやDarts-clone、簡潔木を使ったTxやMARISAなどが有名かと思います。
これらの共通の特徴としては
- ダブル配列を使った実装は高速だがメモリ効率が悪い
- 簡潔木を使った実装は省メモリだが低速
があげられ、そこには時間効率とメモリ効率のトレードオフが存在します。
Xcdatはダブル配列を圧縮領域で持ち、これらのトレードオフを改善することを目的として作られたライブラリです。
ダブル配列辞書としての特徴
XcdatはMARISAと同等の検索操作をサポートします。 既存のダブル配列の実装と比べて以下の特徴を持ちます。
- メモリ効率:Xcdatはダブル配列を圧縮領域で持ち、且つMPトライで余分なノードを削減しているので、高いメモリ効率を誇ります。例えばIPAdicの単語集合では、XcdatはDartsの5.7倍、Darts-cloneの2.7倍のメモリ効率です。(Performance参照)
- スケーラビリティ:多くのダブル配列ライブラリは4バイト整数型を用いて実装されていますが、Xcdatは8バイト整数型を用いて実装されているため、大規模なデータセットに対してもダブル配列辞書を構築することができます。
- 辞書符号化:XcdatはN個のキーワードから成るデータセットを受け取ると、それぞれのキーワードに 0 から N-1 の間のユニークな整数IDを割り当てます。そして、キーワードからIDの検索だけでなく、そのIDからキーワードの逆引きもサポートします。この全単射を辞書符号化といい、データベースの圧縮などで重宝します。
データ構造の簡単な解説
Xcdatがどう圧縮ダブル配列辞書を実現しているかを解説します。
トライやダブル配列の説明は省略しますが、ダブル配列はBASE・CHECKの2つの配列でトライを表現するデータ構造です。BASE・CHECKはノードのポインタ(すなわち配列でのオフセット)を保存する配列で、それぞれ4バイト整数型の配列として実装されることが多いです。
しかし、このメモリ使用量が簡潔木と比べてどうしても大きいです。また4バイトでノードが表現できないような大規模なトライでは、もっと大きな整数型を使用する必要があります。結局のところ、ダブル配列のスケーラビリティには問題があります。
Xcdatでは、この論文で提案されているXCDA法を使ってBASE・CHECK配列を圧縮し、スケーラブルなダブル配列を実現します。手順は主に以下の2ステップで構成されます。
Step 1. BASE・CHECK値の削減
ダブル配列ではBASE・CHECK値をある程度自由に決定することができます。そこで、配列の添字とその要素の値の差分が小さくなるようにダブル配列を構築し、その差分値を代わりに保存します。
具体的には、以下のように添字と要素値の排他的論理和(XOR)による差分値を保存した配列XBASE・XCHECKを構築します。1
XBASE[s] := BASE[s] XOR s XCHECK[s] := CHECK[s] XOR s
1例として、あるデータセットについてダブル配列を構築したときのCHECK値のプロットを示します。左図のように配列の添字とその要素の値は近似しており、右図のようにXORでの差分を取ると、その多くが1バイトで表現できる値(つまり255以下)になります。

この削減は経験的ですが、論文ではいくつかのメジャーなデータセットを使って実験をしていて、すべての場合で9割近くの値が1バイトで表現できることを示しています。2
ちなみにオリジナルのBASE・CHECK値は、XBASE・XCHECKから以下のように簡単に復元できます。
BASE[s] = XBASE[s] XOR s CHECK[s] = XCHECK[s] XOR s
Step 2. 配列の圧縮表現
上の変換により、その値の多くが1バイトで表現できるXBASE・XCHECK配列が得られます。しかし、1バイトで表現できない値も含んでおり、残念ながら単純にバイト配列として実装というわけにはいきません。
そこで、XCDA法ではDACsというランダムアクセス可能な可変長符号を使用してXBASE・XCHECKを圧縮領域で保存します。簡単に言えば、DACsはVByte符号をRank辞書と組み合わせてランダムアクセス可能にするデータ構造です。復元したい値が大きい場合は複数回のRankアクセスが必要となり低速になりますが、1バイト以内で表現できる値はRankアクセスを必要とせず高速に復元することができます。
接尾辞の圧縮
上記の要素圧縮に加えて、XcdatではMPトライとよばれるデータ構造を採用しています。MPトライはトライの葉付近の冗長なノードを文字列に置き換えたデータ構造で、トライ辞書の実装ではよく用いられます。
Xcdatでは更に、矢田らの論文で提案されているように文字列の共通接尾辞を併合することで、MPトライのメモリ効率を改善しています。3
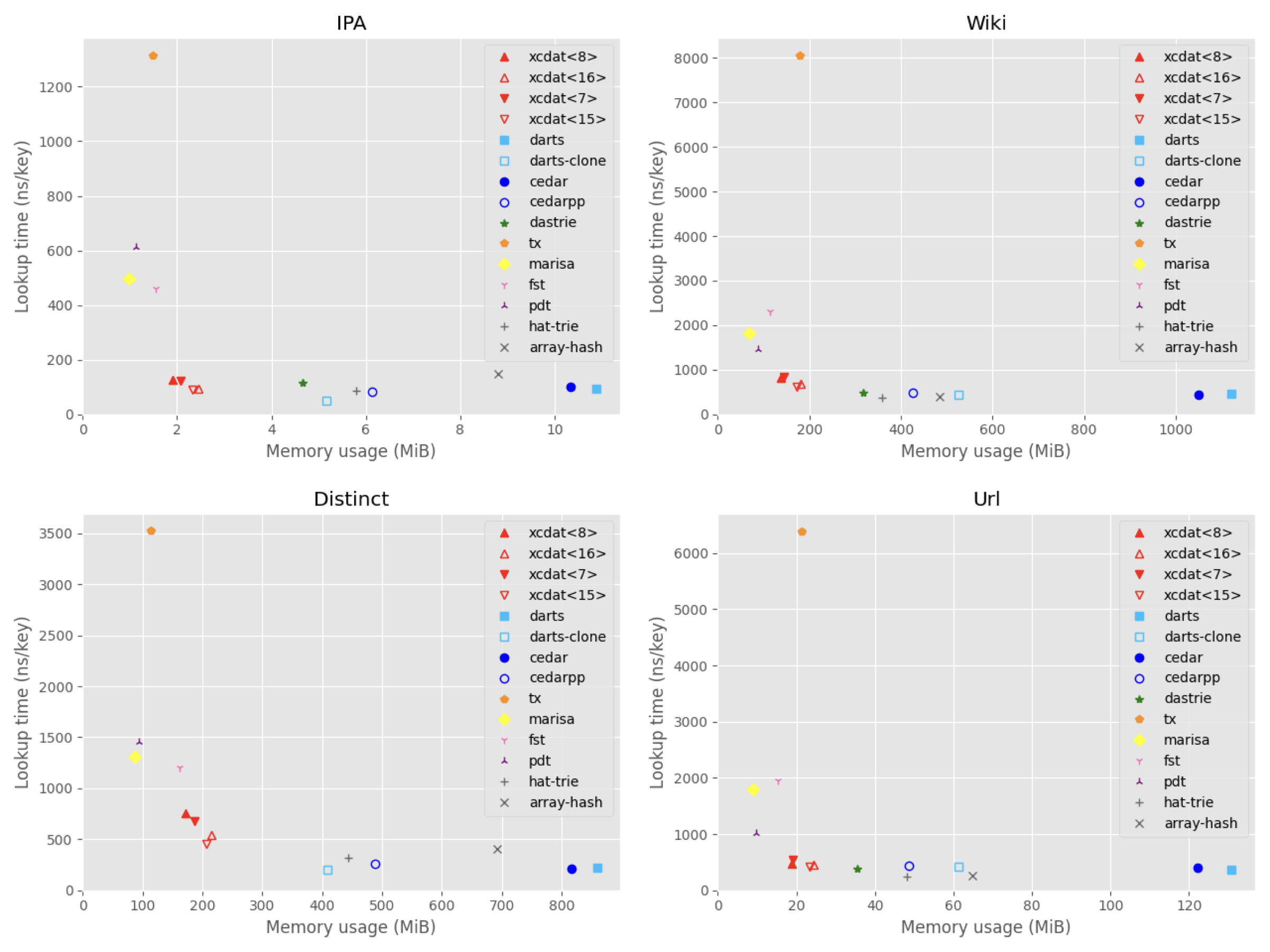
ベンチマーク
Xcdatの性能を私が選出した辞書ライブラリとの比較実験により評価しました。実験設定と具体的な実験結果はREADMEにありますので、そちらを参照していただければと思います。
4つのデータセットでの実験結果として、メモリ使用量と検索時間についてのプロットを以下に示します。大きい画像はこちらにあります。
{kind=link}
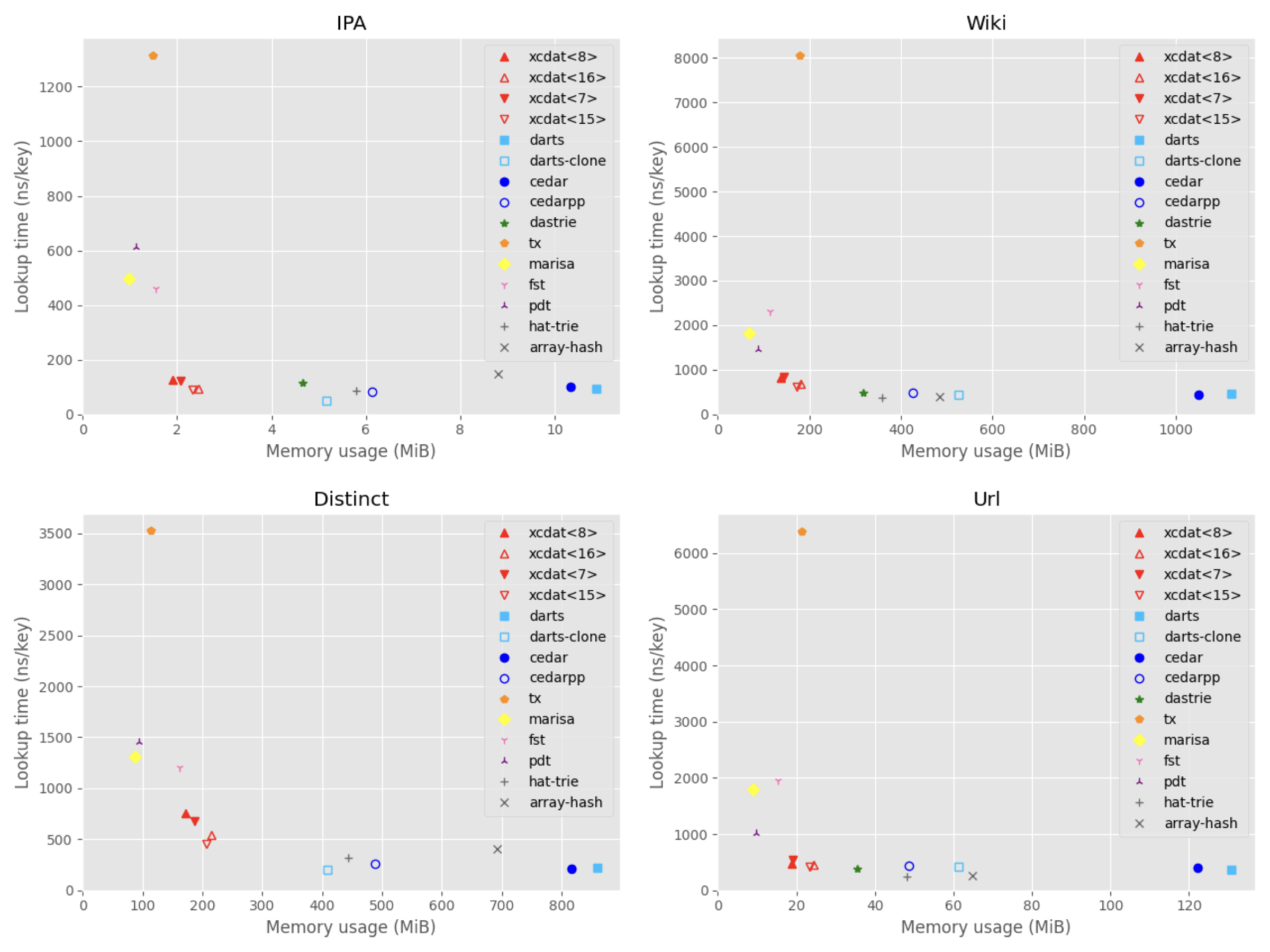
左下ほど省メモリ且つ高速な結果を示しており、Xcdatは良いトレードオフを達成しているように見えます。しかし、Darts-cloneやMARISAと比べて上位互換というわけではないので、目的に応じて活用していただけたらと思います。